A 2025 study found nearly half of AI chatbot responses to medical queries were problematic.
Models struggled with topics related to athletic performance and nutrition.
Recent data shows measurable improvements in model accuracy, yet hallucinations and fabricated citations remain a risk.
Medical professionals recommend keeping prompts specific, using AI for general education rather than diagnosis, and keeping personal health data private.
You can get better AI health advice by grounding responses in verified data.
At some point, you’ve probably felt a phantom twinge in your Achilles at midnight, typed your symptoms into a search bar, and convinced yourself your running career was over. AI chatbots have made that spiral faster and more conversational, but based on a new analysis, their diagnostic skills are still pulling up lame. This report will help you understand the state of AI health advice accuracy.
The Accuracy Gap in AI Health Advice
According to “1 in 2 AI Medical Responses Flagged As Problematic In New Study”, researchers evaluated five popular models using 50 questions spanning several categories. The questions ranged from straightforward facts to the kinds of nuanced inquiries people actually make when evaluating their well-being.
The underlying data comes from “Generative artificial intelligence-driven chatbots and medical misinformation: an accuracy, referencing and readability audit”. This February 2025 study tested several models: Gemini 2.0, DeepSeek V3, Llama 3.3, ChatGPT 3.5, and Grok 2. Experts found 49.6% of the responses were problematic. About 30% were somewhat problematic because they lacked context or oversimplified the topic. Another 19.6% were highly problematic, meaning the guidance could plausibly lead to harmful decisions.
The models performed relatively well on established topics like vaccines, but they struggled with athletic performance and nutrition. Grok generated the highest number of highly problematic responses, while Gemini produced the fewest.
The Trouble with Open-Ended Health Prompts
The way you format your query plays a major role in the output. The BMJ Open audit found open-ended questions generated more misleading information than specific, focused queries.
Chatbots also write with a high degree of confidence and rarely express uncertainty. They deliver answers at a college reading level, which makes the output feel credible even when flawed. When researchers asked the models for scientific references, they found the citations were frequently incomplete or entirely fabricated.
Measuring Recent AI Model Progress
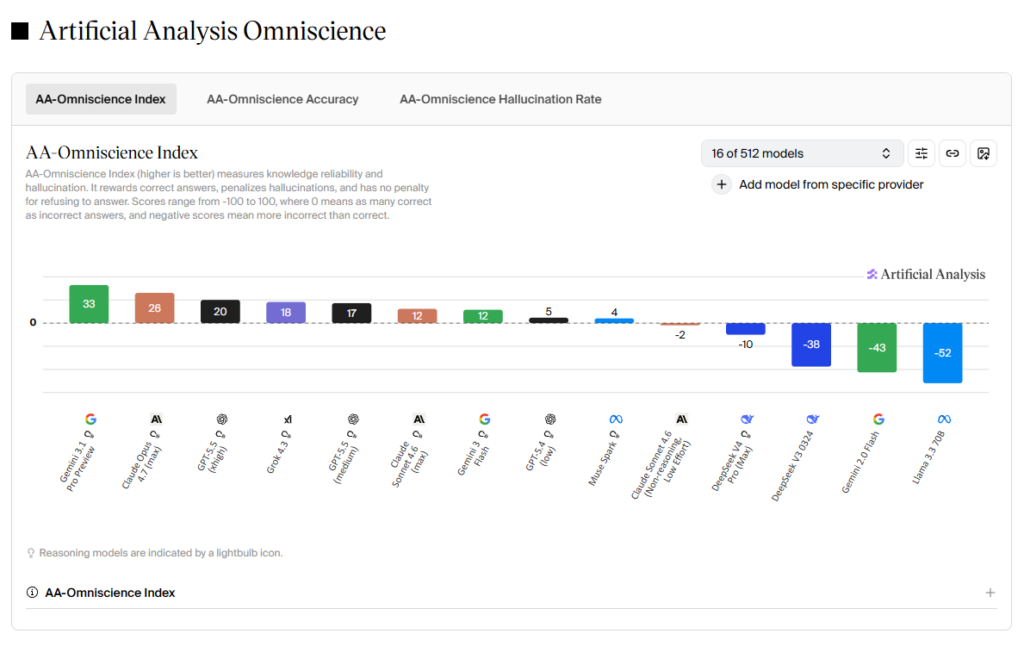
The landscape of AI health advice changes rapidly. To understand the current baseline, we can look at the Artificial Analysis Omniscience Index. This benchmark measures knowledge reliability and hallucination rates across a broad range of topics. Scores range from -100 to 100, where a negative score means a model provides more incorrect answers than correct ones.
The models tested in the early 2025 study have seen updates. Llama 3.3 previously scored -52, and the newer Meta Muse Spark currently scores 4. DeepSeek V3 sat at -38, and DeepSeekV4 Pro (Max) now sits at -10. Gemini 2.0 Flash scored -43, and Gemini 3 Flash reaches 12.
At the time of publication, Gemini 3.1 Pro Preview is the highest-scoring publicly accessible model with an index of 33. Although, free-tier users have limited access to this specific model.
Context and Clinical Reasoning
Measurable improvements in benchmark scores do not translate directly to clinical reasoning. According to “Can you trust AI for health advice?”, a machine cannot diagnose or treat illness because it lacks access to your full medical record and the ability to reason like a human doctor would. AI systems generate answers based on patterns in training data, and this mechanism can sometimes lead to hallucinations. The Mayo Clinic article notes an instance where an AI tool recommended eating rocks to increase mineral intake. Thanks, ChatGPT, but we’ll stick with a multivitamin for now.
Applying AI Health Advice Safely for Your Training
You can use these tools most effectively by adjusting your inputs. Medical professionals suggest using AI for general education, such as asking it to define a specific physiological term, rather than asking for a diagnosis.
Relying solely on a chatbot for health questions and training tips is risky. We recommend feeding the model a data framework to work within, which could potentially lower the risk of errors. You can try pasting a reliable, human-written study or a comprehensive guide from a trusted running coach directly into your prompt. Ask your AI running coach to ground its advice in that verified text. Providing specific, vetted context may help generate a more accurate and useful training plan while limiting the hallucinations common with open-ended queries.
Be sure to cross-check the information against trusted medical websites and verify the existence of any cited studies. Protect your privacy, too – be careful sharing personal information or medical records with a chatbot. You can use AI as a helpful research assistant for drafting questions to ask your doctor, but the final call on your health should remain with a human professional.
Quick Highlights At some point, you’ve probably felt a phantom twinge in your Achilles at midnight, typed your symptoms into a search bar, and convinced yourself your running career was…
The Kiprun Kipride feels and runs like a premium everyday trainer—that is lighter, softer, bouncier, and more stable than many of contemporary models—but it comes in at a lower price…
Need new shoes? Here are 4 great running shoes for $110 or less. April showers bring May flowers, but it also brings some great deals on some very good running…
Join the Six Minute Mile community and get top running tips, fitness advice, and exclusive deals delivered to your inbox. Sign up now and never miss out on the latest updates to keep your fitness journey on track!